


Designing a well-functioning data science team
Team size isn't the only thing that matters!


Ever since I set my foot on management, I’ve always been keen to understand what makes a well-designed data science and machine learning team. Many folks seem to over-index on team size as probably the most important if not the only factor that matters in designing a successful team, mostly in the context of software engineering not data science.
I’ve learned over time that the size of the team isn’t the sole determinant of team design. I actually think it’s not a top priority either. In order for a team to be well-designed and therefore well-functioning, the team should be more autonomous and accountable for business impact, while reducing communication and coordination overhead as well as negotiation overhead with other teams. The team should also clearly understand their role within the company and how their work fits into the overall company objectives which help guide individuals to better, more consistent decision-making.
So what should you do as a manager? Here’s the checklist I put together for designing a successful data science and machine learning team. While it might seem intuitive to some of you and overlap with what you already know about designing an engineering team, laying out a mental model like this helps you be more systematic and strategic about evaluating which part of your team needs more support and deciding where to focus your time and effort on as a manager, especially at early startups if you’re building a team from the ground up and, with limited resources and a lot of moving pieces, need to hone in on that which brings the biggest bang for the buck.
In the order of priority, designing a well-functioning data science and machine learning team in an org requires:
Having a clear mission
Everyone in the team should know what they need to accomplish, what is in and out of scope, and why the team exists. Having a clear mission as part of a larger strategy reduces confusion and guides individual decision-making, e.g. technical system design decisions that limit dependencies across missions.
Investing in all the components and interfaces needed to fulfill the mission
This allows the team to fulfill their mission autonomously without dependency on the successes of other teams. Not only do we need to hire people who possess the necessary skills and knowledge to successfully work towards the mission, but we need to invest in all the components and interfaces that enable them to do so with speed and efficiency.
These interfaces are usually APIs and tools that enable decoupled iteration across teams, e.g. engineering and product teams can iterate on experiences and implementations while data can iterate on algorithms, and that create leverage through re-usability, avoiding creating many bespoke integrations between data systems and engineering systems.
Most data science teams at startups are initially bottlenecked by data engineering and devops teams, e.g. building end-to-end pipelines and secured APIs for machine learning models, and if this is not addressed early enough, we end up divesting our time and effort on maintaining unnecessary dependencies where data scientists handing off their models for these teams to then productionalize becomes more costly as the number and the complexity of models increase over time.
Having clear ways of working
Having clear ways of working both amongst themselves and others outside the team, including dependent teams, reduces negotiation overhead every time there is an interaction. Each and every team should spell out their own conditions for success within the context of existing principles and values of the company.
Frankly, I found this to be the hardest to do when I was at Daily Harvest. In an immature field of data science and machine learning, I was met with several headwinds from stakeholders like marketing and operations wanting to maintain the status quo of data science as a service model where they want us to what we’re told instead of our directly pioneering product innovation and influencing product direction through data and algorithms. Over-communicating my team’s strategic and ways of working north stars as well as demonstrating concrete examples of successful data science projects as a result of those ways of working helped mitigate this issue.
Keeping the team small
Keeping the team small with the fewest members needed helps reduce communication and coordination overhead. We’re increasing the speed of delivery and iteration and the efficiency of decision-making without team members needing every approval from managers and external stakeholders. For data science and machine learning, I found team size somewhere around 3-5 people (fewer than the engineering counterpart) to be manageable because data science managers often wear many hats, influencing leaders at different levels, and the uncertain nature of data science work requires managers to be flexible and hands-on.
Having the diversity of skills and perspectives
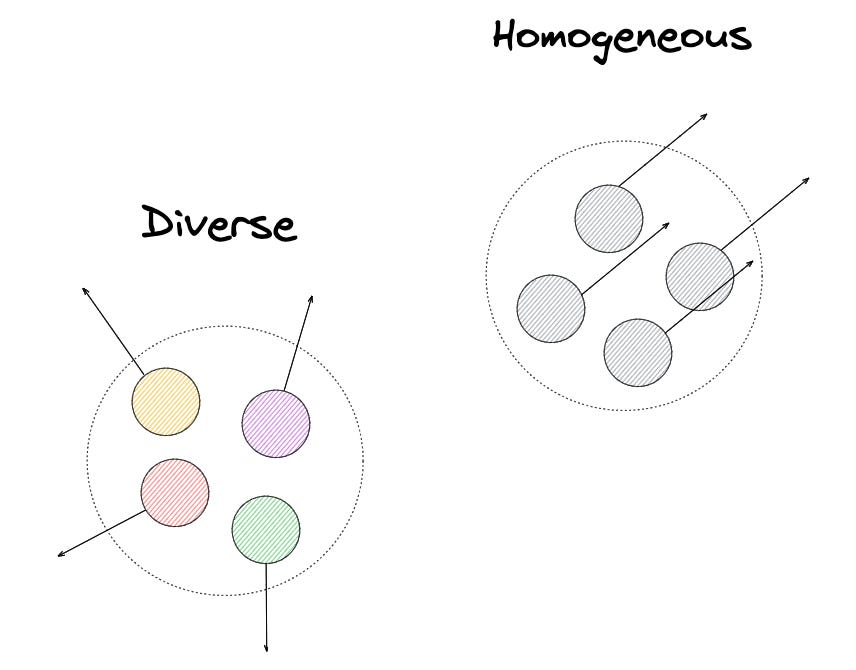
Actively hiring team members with diverse and complementary set of skills and perspectives, partly a manifest of the diversity of racial and socioeconomic background, can’t be overlooked.
At Daily Harvest, many of our biggest wins often came from thinking about old problems in new ways, reframing them and taking new approaches that span multiple academic disciplines due to the data-rich environment of our business as well as the diversity of the problems we take on from personalization and recommendations to culinary and operations.
While homogeneous teams tend to move faster in one direction than diverse teams, they tend to get stuck in a local optimum often and end up reaching a wrong end, and it’s difficult for them to break free from it. Diverse teams, on the other hand, might be slow to move initially due to healthy disagreements rising from different perspectives but usually end up finding an optimal solution, often with battle-tested conviction.
I hope these help!
About this newsletter
I’m Seong Hyun Hwang, and I’m a data scientist, machine learning engineer, and software engineer. Casual Inference is a newsletter about data science, machine learning, tech startups, management and career, with occasional excursions into other fun topics that come to my mind. All opinions in this newsletter are my own.