


How Direct-to-Consumer (DTC) brands can guide the customer experience from start to finish
Personalization and recommendations in action: winning strategies and tactics 💯

Today I’m writing how DTC brands can design the end-to-end customer experience that leverages personalization and recommendations.
This is based on my personal experience working at several DTC startups over the past years—I’m excited to share my thoughts, opinions and practical tips from a data science and machine learning (ML) perspective on how DTC brands can win customers and keep them for life.

So many products nowadays are getting launched in the direct-to-consumer (DTC or D2C) route. From plants and custom shampoos to food supplements and meal kits, going DTC has several benefits: brands own their supply chain pipelines with no middlemen (e.g. third-party retailer and wholesaler) leading to more bottom-line profit control and can personalize the end-to-end buying experience that optimizes customer satisfaction and engagement.
DTC products are often perceived to be complex and unique that they need to be tailored to individual custom and the education process can feel overwhelming. Take the example of custom shampoos. How do I know which shampoo is right for me? It depends on a variety of factors like hair texture, length, density, and even my lifestyle and hair goals that need to be learned during the onboarding process and over time. It’s complicated. I might also want to know why they matter and how using custom shampoo will help me maintain healthier, fuller and shinier hair. People aren’t just buying custom shampoos, but they’re buying better hair care accompanied by lifestyle changes and good habit formation. They’re looking to harvest their preferred emotional state upon buying what they love to reduce post-purchase dissonance, and they love brands that can help them find a better version of themselves.
“People don’t buy for logical reasons. They buy for emotional reasons.” — Zig Ziglar
Guide vs shop
DTC brands that know this develop deep customer loyalty by creating an end-to-end experience based on discovery and guidance. We the business should seek to support customers along their unique journey, leveraging everything we know about them and our products to deliver what they love. When possible, we should minimize the burden on customers to know what they want (customers shouldn’t need to know exactly what they want or even how to find it) and manually explore large catalogs of complex products (we should find the most relevant products for the customer without them having to do the work). Our job is to bring simplicity and delight to complex products.
Customers shouldn’t need to know exactly what they want or even how to find it.
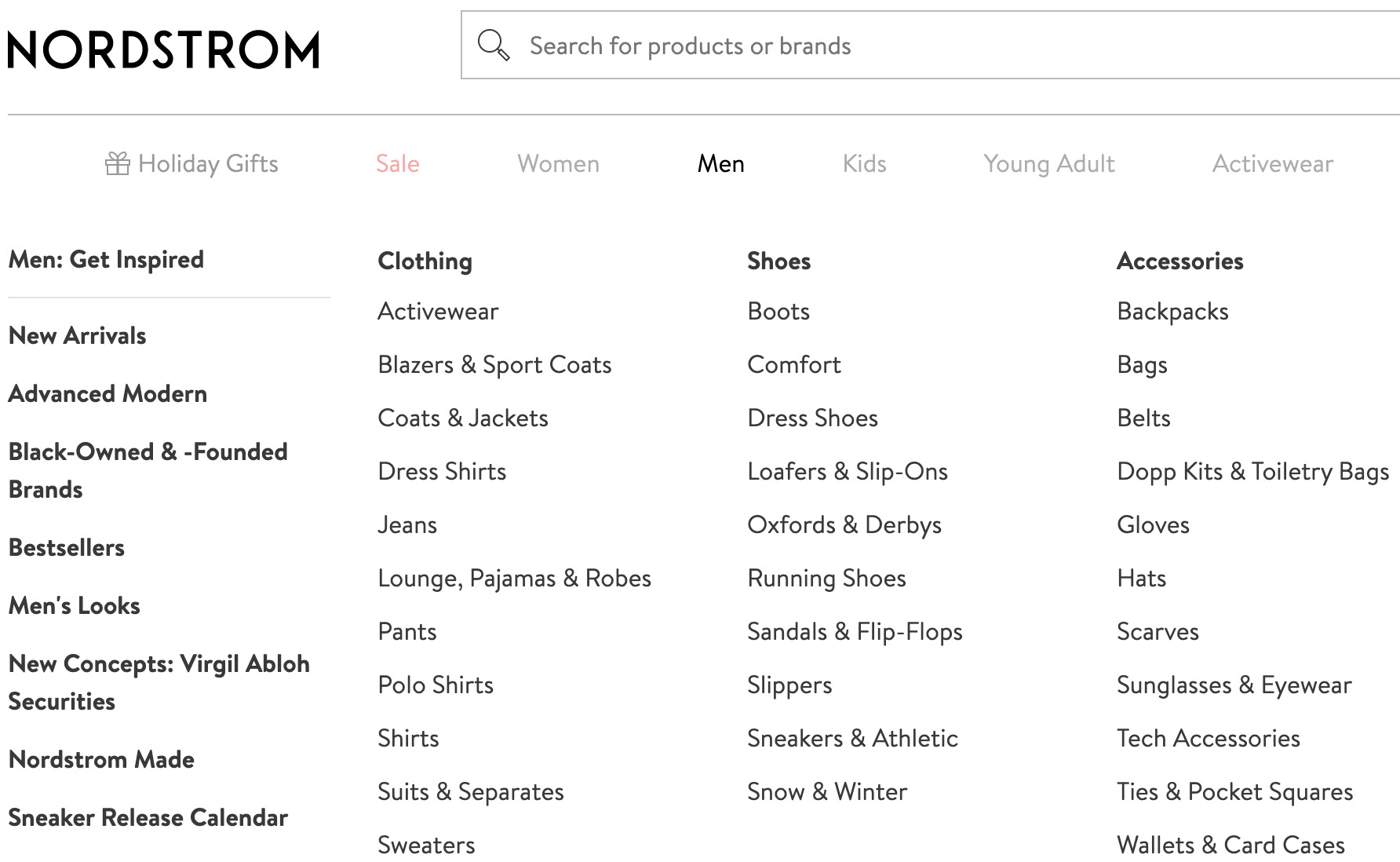
Many retail and e-commerce companies like Nordstrom and Walmart build a “shop” where you the customer is expected to know exactly what you’re looking for, but they’ve never been very good at helping customers effortlessly find what they love and discover the unexpected. It’s inconvenient in so many ways: you’re forced to search and scroll for products, and the vast majority of what you’re seeing is not relevant to you. These companies don’t have an in-house recommendation team, and even if they do, they rarely have a business model that supports “guiding” customers along their journey1 and getting to know them better to get more relevant products in front of them.
The experience starts with discovery from a “cold-start,” helping prospects2 find the best product by learning their needs and preferences during the onboarding journey and educating them along the way the benefits of our products. We want to make customers feel like “we know them,” setting clear expectations and aligning with values of personalization. We want customers to help us support them by getting feedback that improves our recommendations offering surprise3 and delight moments at every touchpoint. Every person is unique, and their needs and wants are context and mood-dependent, and even non-stationary. No two products are the same either. No two customers are expected to have the same path to discovering the products they love and end up buying over and over again.
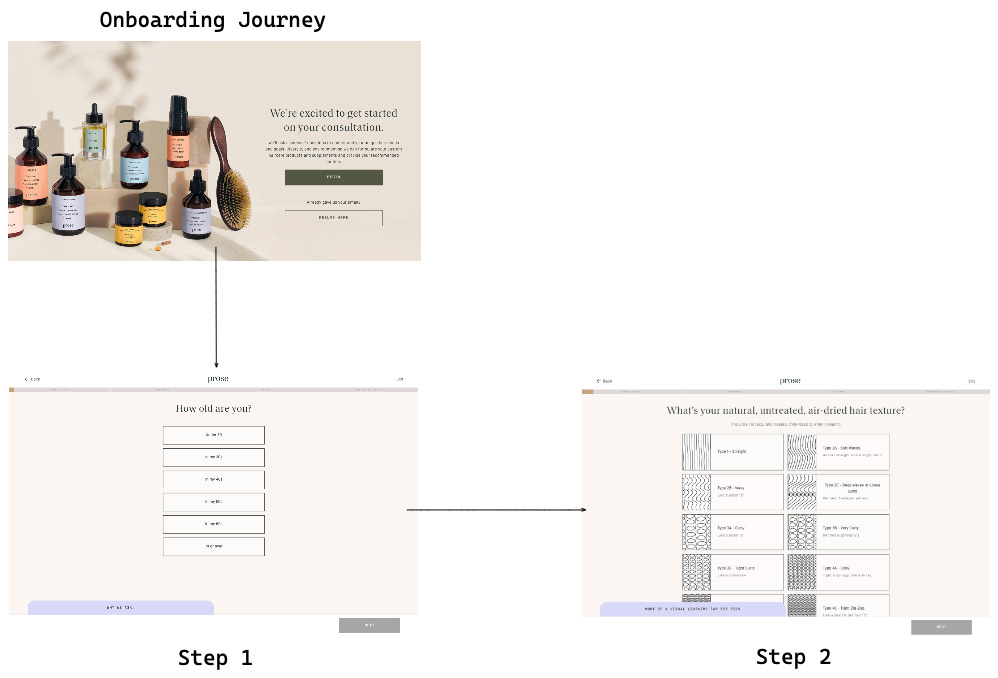
Revisiting our example of custom shampoos, Prose crafts an exceptional onboarding journey that takes every customer through the quiz that seemingly recreates the dialogue your best sales associate will have with them (Figure 1). Rather than customers doing the research and discovering the right product for themselves, they are guided through the “help me choose” (or “help me customize,” in this case) experience and educated along the way why the questions being asked matter to getting the perfect custom shampoo they’re looking for.
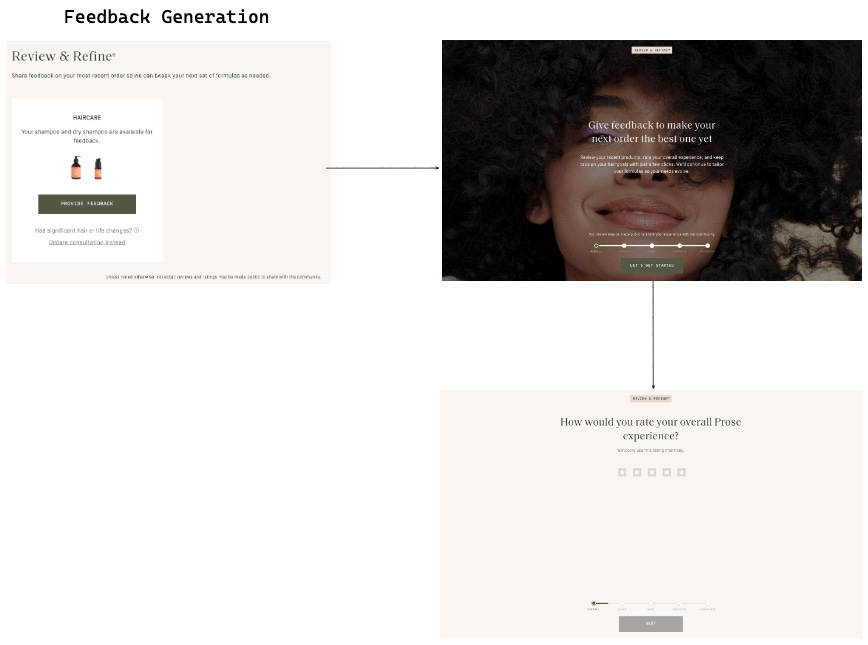
After the initial purchase, the customer gives a detailed feedback on the different dimensions of custom shampoo (e.g. scent) and hair care (e.g. scalp, oiliness), and the business uses the feedback to refine the custom shampoo formula for the next order (Figure 2). By getting customers to engage with the brand and help the brand learn more about them, we’re making sure they’re always stocked with the product they want and form a good habit with it.
Even if it’s not about customization at an individual level, any DTC brand (e.g. Rooted, StitchFix, Care/of, The Farmer’s Dog, Daily Harvest) selling many complex4 products requires getting the right product to the right customer at the right time (personalization and recommendations) and leveraging customer feedback to develop the right product and iterate to improve it over time (we want to make products that customers want to buy!).
Ultimately, creating a guided shopping experience that is tailored to the individual customer needs and preferences is pivotal to brand perception, customer satisfaction and loyalty. While there aren’t hard-and-fast rules and what works depends on the domain and the particular problem, I’ll share some of the winning strategies and tactics on designing the customer experience that leverages personalization and recommendations I helped pioneer for my team that eventually won the customer.
To the best of my knowledge, there are no publicly available resources that do a deep dive like this. What you’ll read here can be extended to other business settings, so any astute reader should be able to take away a couple of interesting ideas.
You probably don’t need a search bar 🔎
“The Web, they say, is leaving the era of search and entering one of discovery. What’s the difference? Search is what you do when you’re looking for something. Discovery is when something wonderful that you didn’t know existed, or didn’t know how to ask for, finds you.”
— CNN Money, “The race to create a ‘smart’ Google”
Many of us love search (full disclosure: I don’t). Search is the functionality that offers customers a way to find products with speed and ease, and we see it on almost all modern e-commerce and retail websites. The mistake is, however, to blindly take the search feature from these sites and apply it directly to DTC setting (I’m looking at you marketing and merchandising folks 🙄). Rather, we should focus on understanding what is the universal customer need that search is trying to solve and how adding a search bar can harm (or benefit) the discovery and guidance based customer experience we want to create.
As I said earlier, most DTC brands sell complex products that people have little idea what they are. How are customers supposed to use search if they don’t know what they’re looking for because they aren’t quite sure what our products are? If we’re building search to capture data on customer preferences, how valid and reliable are those data if only a small number of customers are expected to use it? Adding an on-site search could place the burden of discovery on customers.
When the burden of discovery is placed on customers, search becomes a natural fallback for finding relevant products. An on-site search as the center of experience is the first thing that customers see on the site, and it naturally becomes the go-to place for discovery. While this might sound benign at first, if customers can search relevant products for themselves, why would they go an extra mile to help us improve our recommendations? They feel less inclined (and less obligated) to provide detailed explicit preference data5 because there are no tangible incentives in doing so (except if and when a product is extremely bad, for the sake of monetary compensation, or extremely good6, a state of high evangelism7).
More importantly, we the business become far too reliant on optimizing search rather than learning more about customers that make recommendations better. This makes little sense for the business with its own technical strategy of leveraging personalization and recommendations that is solely responsible8 for getting relevant products in front of each and every customer. The customer shouldn’t need to figure out what’s right for them, but we do! We want to form a long-term relationship with our customers that is less transactional where the benefits go both ways—customers provide detailed explicit preference data to help us help them, and in return, we suggest extremely relevant9 products we believe they’ll love that reduce the burdensome task of shopping.
Instead of search, my suggestion is to invest in browsing and leverage the recommendations to deliver the optimal browsing “state” that’s unique for every customer and changes over time.
Visual navigation
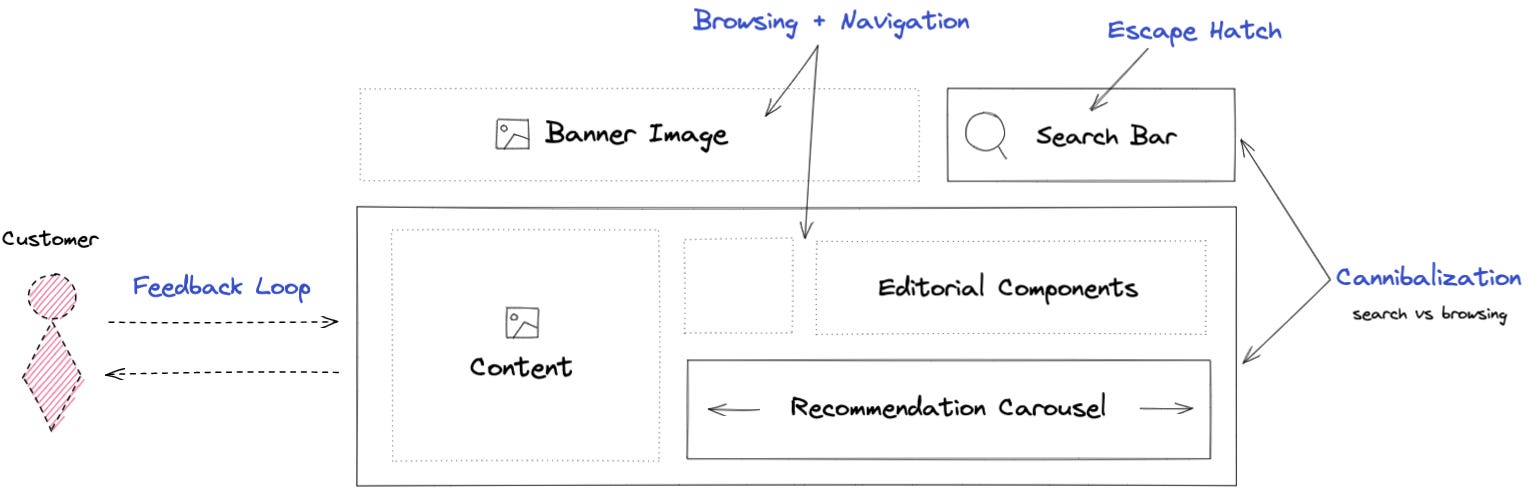
User research and tests have consistently shown that visual navigation is a big winner for both existing and non-customers. An instance of what I believe is a great example of browsing and navigation comes from CookUnity (Figure 3), a chef-prepared meal delivery startup. Some meals and ingredients like fonio, polenta, and chimichanga are hard to understand if you’ve never tried them before. No two chefs make the same chicken marsala either. Meal photos are helpful for understanding the categories and the products that seem obscure to customers. Carousels and grid-like designs provide engaging storytelling. Top-level groupings (collections) support multiple ways to navigate (items10 could belong to multiple collections) and enter the experience and make it easier for customers to focus on key information that matters.
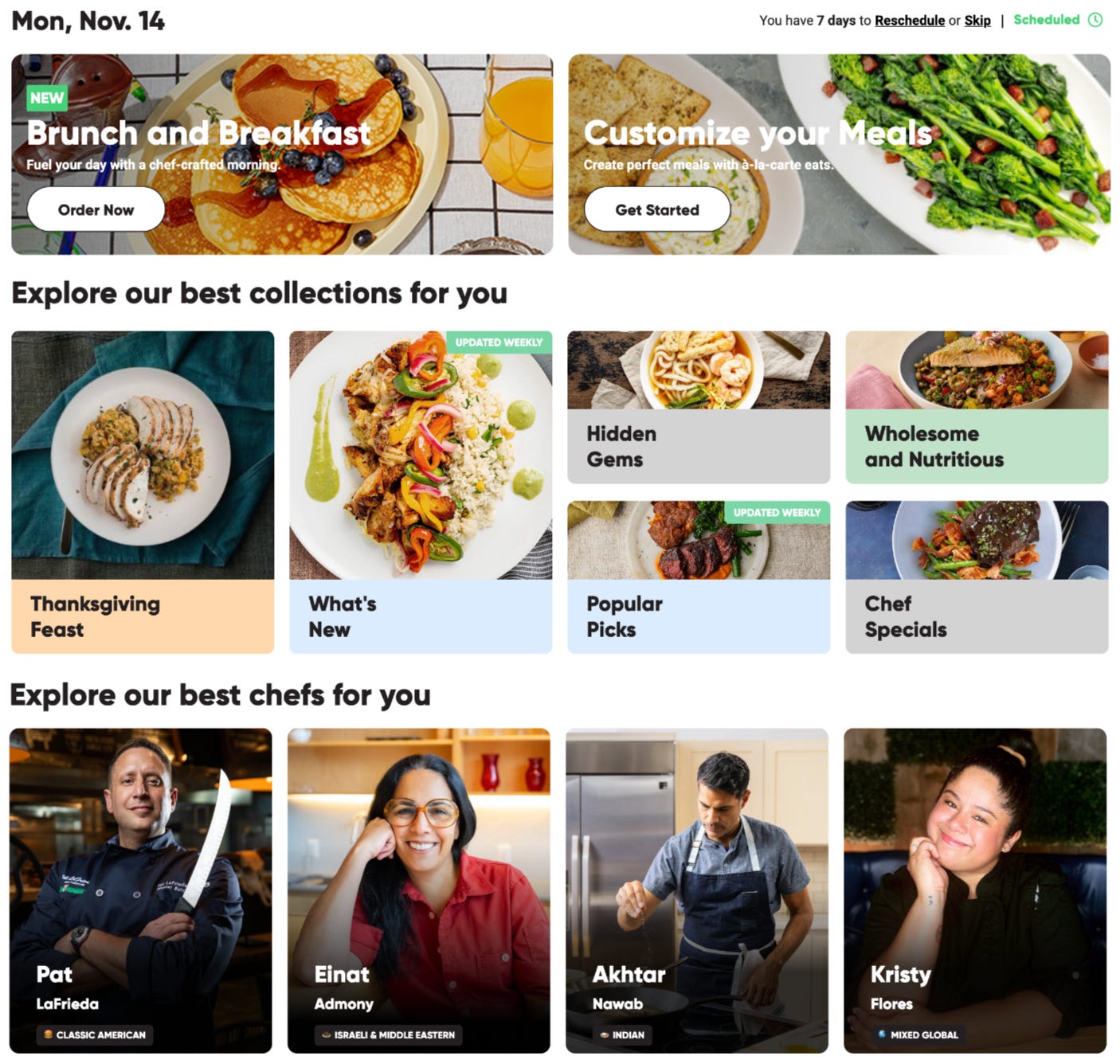
Each customer will see a unique layout (browsing state) that changes over time based on everything we know about the customer and their interactions with the contents on it. If I’m a huge breakfast eater, for instance, I might see the “brunch and breakfast” card and other similar cards more often on top of the page, with occasional new cards that expand my taste. When I click on the “brunch and breakfast” card, meals will be algorithmically ranked according to my taste preferences.
This is a far better experience than merely displaying an exhaustive list of ever-growing links (link farm) at the top of the page (Figure 4). This sort of global navigation experience might make sense when building a shop, not a guided discovery experience.
With the right browsing and navigation experience in place, which should be evaluated empirically, we can reduce the cognitive load of customers having to look through the entire catalog by surfacing only a few we believe they’ll end up buying.
Contextual bandits
So how exactly do we create this optimal browsing state that’s unique for every customer and changes over time? As I wrote in my previous post, we can leverage contextual bandits for all sorts of recommendations including the algorithmic construction of the home page so every customer see a unique home page that is reflective of their preferences (e.g. past order history, customer profile, ratings, feedback), context (e.g. time of day, device type, season, location), and engagement (e.g. clicks, views, scrolls, add-to-carts) with the contents on it.
What rows (modules, components, carousels) to show and what to show in each row (items) might differ across the users and change over time. Essentially, contextual bandits are used to dynamically show (or hide) and rank different items and components for each user.
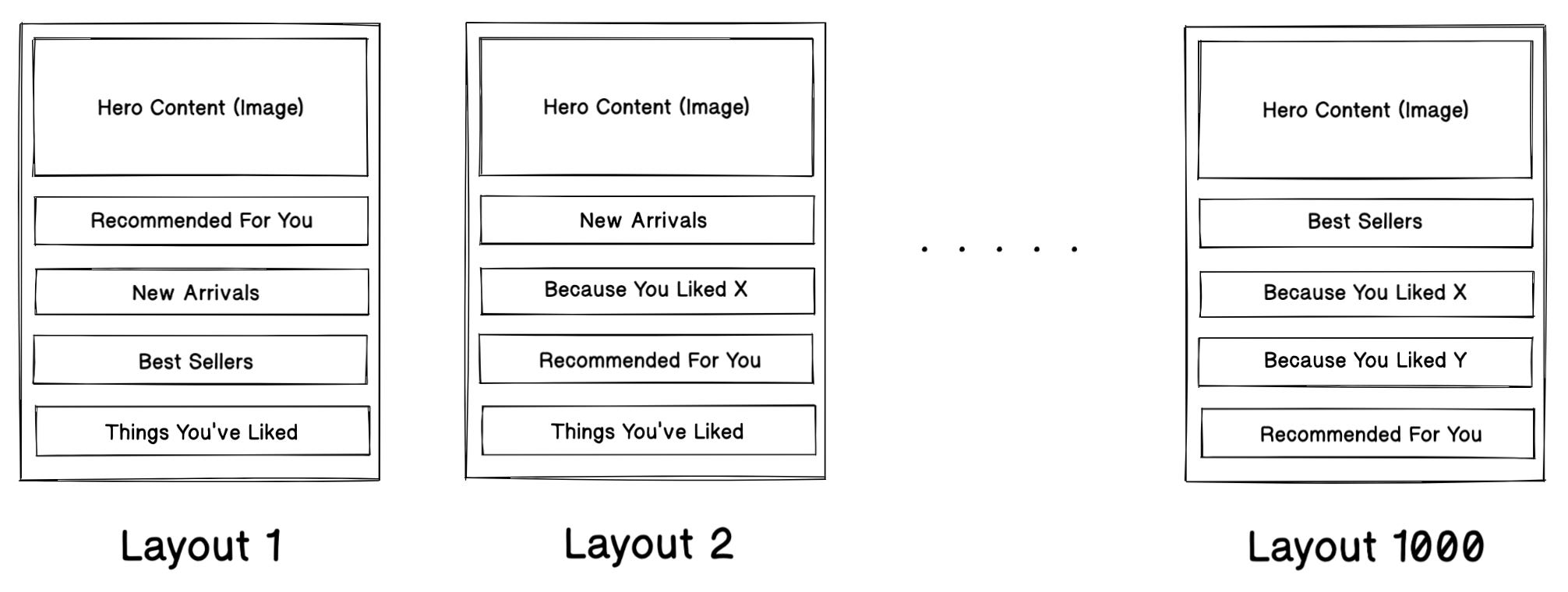
Say we have 1000 total impressions for all modules (Layout 1, Figure 5):
100 impressions, 10 clicks, 4 add-to-carts for the “Recommended For You”
50 impressions, 3 clicks, 6 adds for “New Arrivals” module
For a given customer, which of the two modules should we rank higher on the home page? The number of interactions (clicks + adds = 3 + 6 = 9) is lower on “New Arrivals,” but an add-to-cart is a stronger signal of purchase than a click so we should probably weight it higher. On the other hand, “New Arrivals” has fewer number of impressions than “Recommended For You.”
It’s non-trivial to implement contextual bandits from the get-go and battle test their effectiveness against the baseline, so my recommendation is start with a simple multi-armed bandit to begin collecting unbiased data that you can use to train a contextual bandit model, and then at a later point in time, transition to a contextual bandit.
On truncating, chunking, and hiding
Truncating the output of recommendations, chunking11, or even intentionally hiding (not showing) them can greatly improve the customer experience by reducing the cognitive load and eliminating the possibility of bad experience.
Truncating is only showing extremely relevant recommendations at first and showing the rest if and when customers want to see them (e.g. show them the next chunk of recommendations upon their clicking a button “show me more recommendations”). Chunking is showing in groups or chunks to keep the information contained and focused. Hiding is never revealing bad outputs (these don’t always need to be items with p < 0.5) to minimize the bad experience.
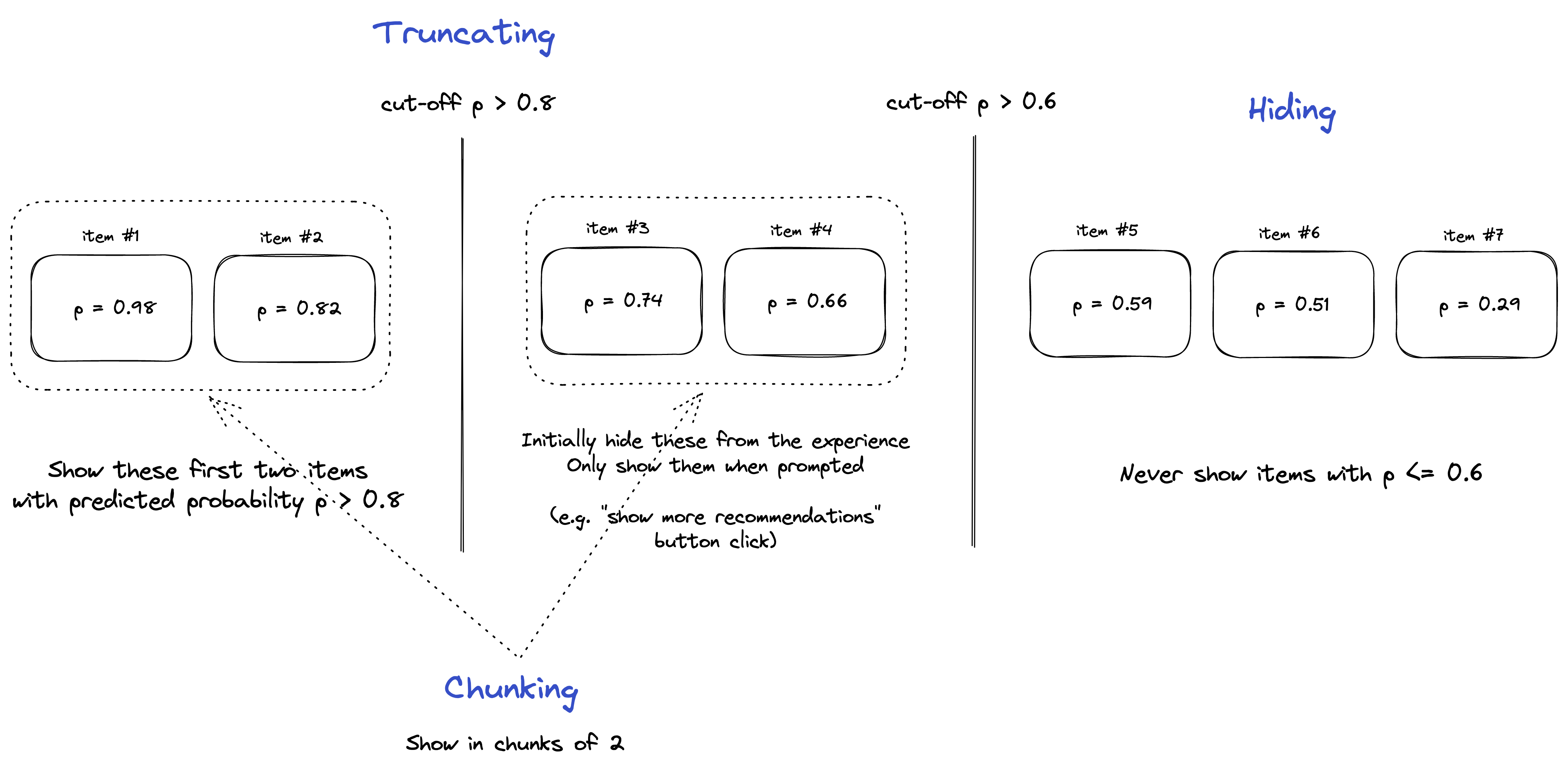
Remember why we need to provide extremely relevant recommendations?12 We probably want to optimize for precision over recall, but if we end up showing only the topmost items (p > 0.8 as in Figure 6), we might run the risk of showing too few and terminating our interaction with customers too early. Truncating avoids this saddle point by showing the next set of relevant items (0.6 < p <= 0.8 in Figure 6) only if and when customers don't find the initial recommendations useful and therefore explicitly consent to see additional recommendations.
On the same line of reasoning, if you were so upset about your recently purchased meal kits, instead of nudging them toward the bottom of the menu and recommendations, we should completely hide them so you never see them.
Truncating, chunking and hiding13 are the elements in experience design that work in tandem with the recommendation algorithms to reduce the cognitive load and streamline the customer experience.
So we shouldn’t add search after all?
This all seems so counterintuitive! Perhaps I should say there’s probably a role for search more as an escape hatch than the center of experience. This could mean making a search bar smaller than the browsing and navigation experience and making it do a simple regex matching on keywords instead of building a full-blown ML search solution upfront.
In search, you are “looking for” a specific result, while in browsing, you are “looking at” general ideas or multiple answers. Some customers don’t want to think about anything when it comes to buying (so the business is doing the heavy-lifting of delivering the right product in front of the customer), but we’ve also got customers in the other end of the spectrum who want to participate in the shopping experience. Search can augment the experience of late-life customers who are already very familiar with the products when they know exactly what they need. In some cases, it could be worth testing adding a search bar on the non-customer (signed out) experience that ultimately leads to the guided onboarding experience.
From a data science perspective, search can be leveraged as a way to prevent the unintentional feedback loop, which makes biases to be reinforced by the recommender system and reduces the usefulness of the system (this can happen when you show recommendations and people can only interact with what’s recommended). With search, people are still able to buy things outside the control of the recommenders, and we can leverage some search data to not only predict what someone is going to buy but also predict what the system would’ve shown to the customer in the past i.e. did you buy a product because we recommended to you, because you wanted to buy it anyway, or both?
If the business decides to add search later down the road for whatever reason, it needs to make sure that search doesn’t become the center of experience and the output of search does not cannibalize the performance of the recommendations in the existing browsing14.
Feedback loop 🔁 informs personalization and co-creation
Designing a positive feedback loop is a key to making better recommendations and getting customers engaged in the product development throughout their lifecycle.
The core questions to keep in mind are generally:
What are the different dimensions of products we can get feedback from our customers?
What kind of underlying attributes and types of data could we get through customer feedback that might be helpful in thinking about the early iterations of customer profile (either attributions of products or parts of the catalog, or even getting better information from customers, particularly first-time customers15 e.g. what sort of questions can help us predict their LTV, life-time values)?
How can we use customer feedback to build better products?
Beyond ratings and feedback, can we design a new engagement experience so customers at all lifecycle continually engage with us without hitting the saturation point on utilization? What new experiences can we design to help us understand customers better?16
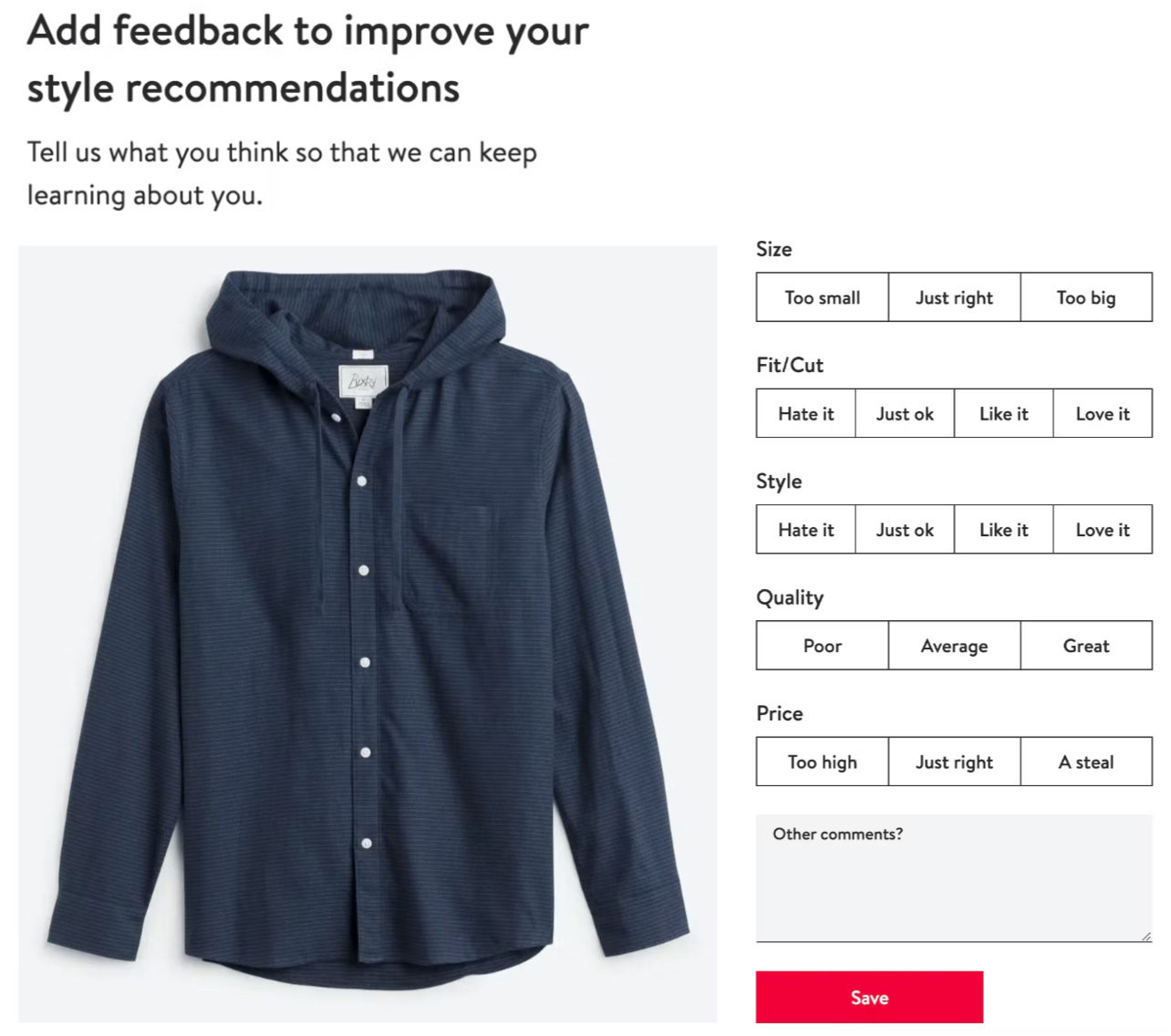
At StitchFix, every time a customer receives an item from their Fix or Freestyle, they’re given the opportunity to add feedback on different dimensions of clothing items to improve their style recommendations:
At Daily Harvest, customers can leave ratings and detailed feedback for items they purchased and tried (Figure 9). With these ratings and feedback, we can fine-tune our recommendations by learning different taste preferences and even understand, for example, which products do customers generally perceive to be spicy and even whether the level of spiciness is too much or good enough. This helps the culinary team iterate on the food they develop and come up with a better version over time (e.g. is the smoothie too tart? let’s make it less so by using less of or even swapping out certain ingredients).
Explicit ratings and detailed feedback help us understand different taste preferences and guide us on how we should be developing what we develop. They help us identify underserved customers and opportunities to expand the existing product options.
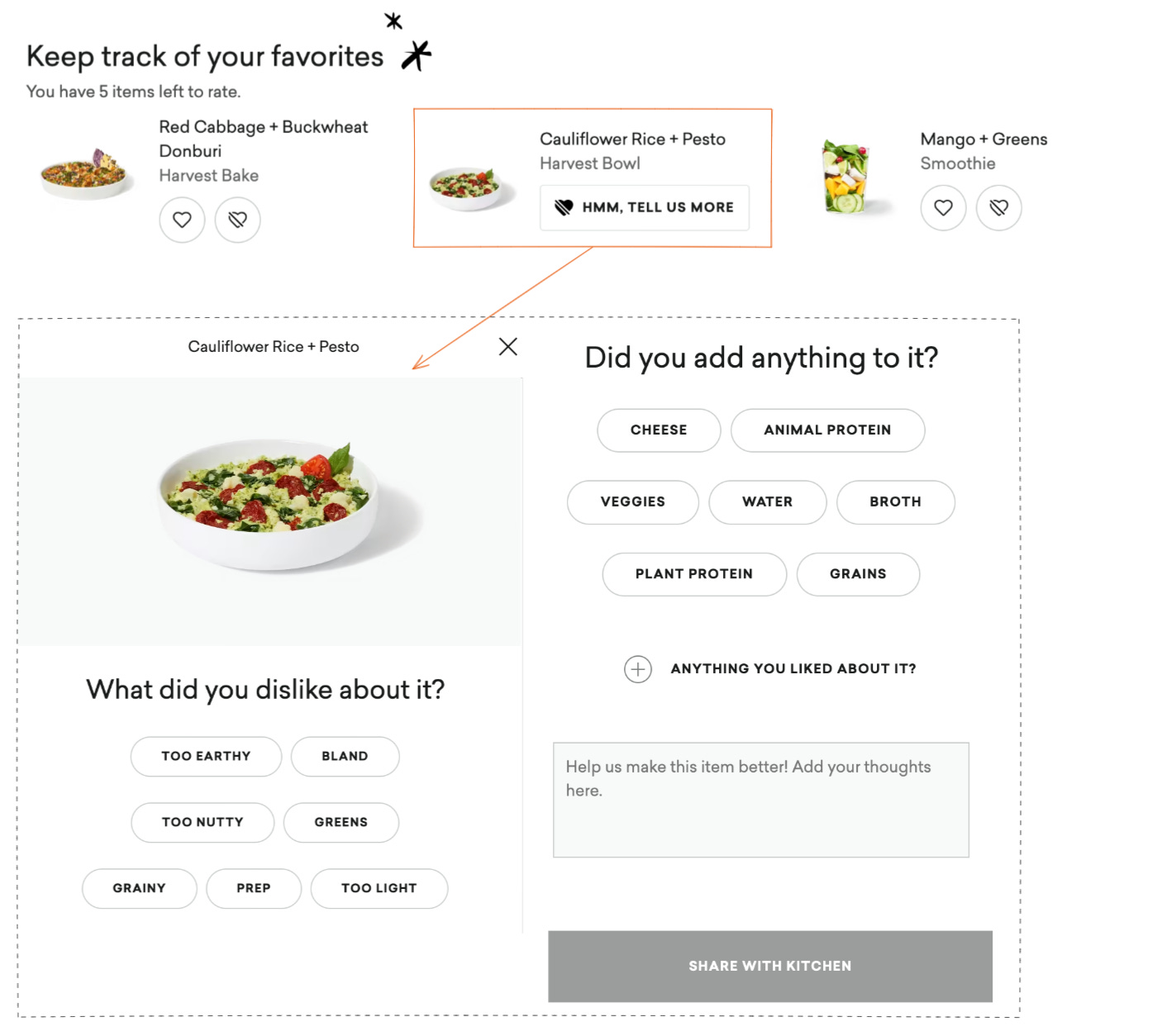
Ultimately, we are interested in what allows us to change the way we engage with our customers—how changes in our products help customers or what new products we should be developing (co-creation). By demonstrating co-creation and keeping customers engaged between purchases with useful contents, hacks and tracking, we are helping customers form good habits with our products in the long run.
Build a centralized customer profile
DTC brands leverage customer data to personalize the end-to-end buying experience, and the best kind of data they can collect is the first-party data, which is information collected directly from customers and owned. Beyond typical event data (e.g. clicks, views, scrolls, page loads, search strings) captured by your data engineering team, we can simply ask questions directly to customers: what do you like and dislike? What do you want to see more of?
A centralized customer profile is a place where customers could state and control explicit preferences about themselves and the different dimensions of products. This is where we learn more about the customers so we can tailor our recommendations to their preferences.
Figure 10 illustrates another example from CookUnity that lets you specify your meal preferences and tells you exactly how they’ll be used. I might have certain allergies and ingredients I want to avoid. The key is to limit it to pretty objective things, not subjective: I want keto diet (explicit, objective things) vs. how spicy I like things (subjective). Because people are generally not good at describing their preferences, we better let them explore and learn them mechanically than they describe them. We don’t want to filter out too much of the inventory up front based on those preferences.
“People don't know what they want until you show it to them.” — Steve Jobs
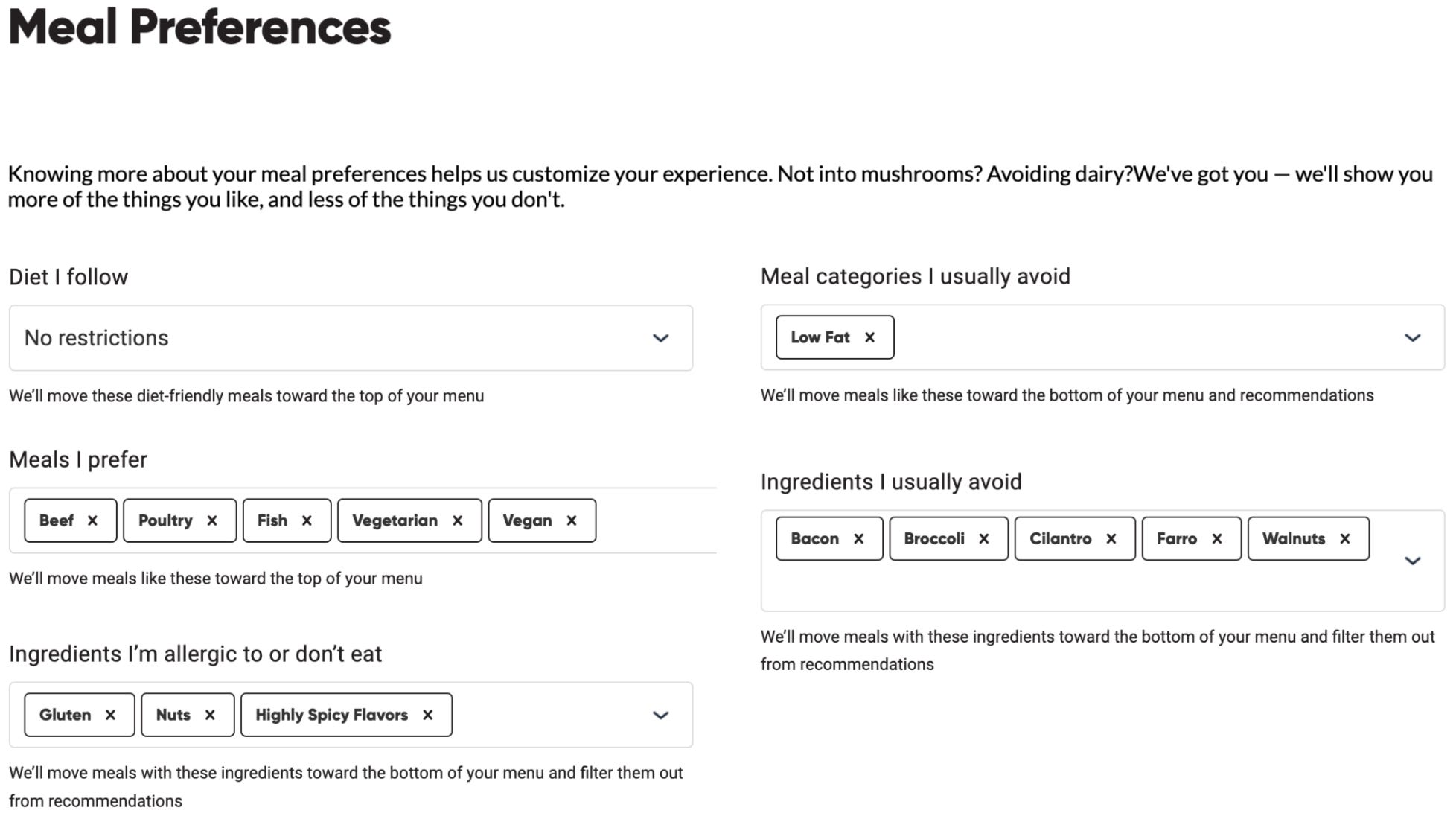
Let’s take an example: I hate cilantro and want to avoid all meals that have it. But I might not taste it at all in some meals that have it, either because the amount of cilantro is so small (maybe it’s used as a garnish so I can take it out) or it’s thoroughly cooked with garlic and onion so their putrid smell is gone. What matters is am I avoiding cilantro because I don’t like the taste, which is a matter of preference, or because I’m allergic to it? In the case of the former, it might still be worth nudging to try some meals with cilantro if the algorithm believes you’ll like the taste of the overall meal despite my dislike for cilantro.
Ideally, we’d want all customers to fill out their profiles so they can help improve our recommendations, so many companies ask these preference questions in the onboarding journey (remember the Prose onboarding quiz?) that customers can later update in their profile.
When we have a centralized customer profile, where do the filters live? In the browsing experience? Can filters co-exist with the customer profile? Browsing filters (e.g. sort by, dietary needs, likes, dislikes) are similar to search functionality in that we’re passing the burden of discovery onto the customers. Nonetheless, all these questions should be answered and validated through user research and experimentation.
Multi-user interface
Sometimes you’re not just buying the product for yourself but for your spouse, children, or friends. These people have different phenotypes, preferences and values, and we should be able to speak to them as individuals, capturing granular individual data and associating it with the account level. Think Netflix—you can have multiple user profiles under one account so each individual’s preferences are not getting mixed up with the other users in the same account.
Investing in the multi-user interface helps us capture better data and differentiate preferences that inform personalization and recommendations. Some companies ask in the onboarding journey whether you’re filling out the customer profile for yourself or for others on their behalf, so they know exactly who the recommendations are for going forward.
Removing biases and negative feedback loops
While we have positive feedback loops that amplify the customer experience, biases can occur in different stages of feedback loop that work negatively on capturing the right signal for personalization and recommendations. There are many biases that exist at the intersection of the user, data, and model that go beyond the topic of this post, but I’ll briefly share a couple that I feel are somewhat controversial.
Removing public 📢 reviews and ratings?
Public reviews and ratings can influence your own rating and interaction with the item. Even if the recommender system thinks you will love the item you haven’t tried yet, if you see bad public ratings on it one after another, you might be hesitant to try it no matter how many times we recommend, which is a huge missed opportunity for the business. Similarly, even if you thought the item you tried is great, upon reading a number of bad reviews on it, the item might no longer seem as appealing as you thought it once was.
This is called conformity bias where users tend to rate and behave similarly to the others in a group even if doing so goes against their own judgment, so the rating values and feedback do not always represent the true user preference. And this is probably why Netflix doesn’t have any public review or rating on their site.
On the other hand, public reviews and ratings can help you make better decisions. If an item is popular and best-selling, you’ll probably like it, unless you’re an outlier. Recommending popular items to cold-start users works well when we don’t have much information about them.
Binary ratings? 👍 👎
Netflix moving away from 5-star ratings to binary was probably one of the most controversial decisions. Many say that it’s useless. While binary rating could potentially prevent customers from rating items they aren’t sure about, from a recommender system perspective, it gives more confidence to the ones you do rate and forces you make the choice between surely bad and surely good, which is a far richer signal to act upon than a 3-star rating.
Not long ago, Netflix released a new “two thumbs up” feature as a way for users to express how much they love the show. This could help recommender systems capture and distinguish a strong signal of love from a rather weak signal of like without introducing the unnecessary complexity of the star rating.
Putting it all together
Creating an integrated journey that brings the customer along from trial to personalization to replenishment and a frictionless experience that deepens engagement and fuels habit formation are pivotal to the success of the DTC business model. DTC brands should design a guided customer experience that leverages personalization and recommendations in every way possible.
Acknowledgment
A huge thanks to on for reading drafts of this post and providing helpful suggestions for improvement. She designed the logo for my newsletter Casual Inference. Subscribe to her newsletter below:
Random quote of the day
About this newsletter
I’m , and I’m a data scientist, machine learning engineer, and software engineer. is a newsletter about data science, machine learning, tech startups, management and career, with occasional excursions into other fun topics that come to my mind. All opinions in this newsletter are my own.
Specifically, the onboarding journey is not just limited to the acquisition funnel. It comprises the entire experience leading up to the aha moment.
Prospects are often defined as non-customers who’ve expressed some interest in the product you’re selling. In most online businesses, this means giving their personal information (e.g. email addresses, phone numbers) at the start of the onboarding journey.
In the recommender system literature, we call this serendipity (unsought finding) where we don’t recommend items (products) the user (customer) already knows or would’ve found anyway. How do we expand the user’s “latent taste” outside at their margin?
Is it better to get customers to try something new or drive loyalty with previously ordered items? At which point do customers feel fatigue from repeatedly ordering the same set of items? Different recommendation strategies appeal to different subset of customers, but in general, my experience has been that expanding their taste into neighboring areas and making it more diverse improves the overall engagement.
Serendipity is related to the explore vs exploit dilemma (how much do we explore items we don’t know users are going to buy or not vs leverage what we know about the user) as well as the causal impact of recommender systems (did you buy a product because we recommended to you, because you wanted to buy it anyway, or both?).
A product is deemed “complex” when individual components, characteristics, or ingredients that make up the product are lost in the complexity of the whole. For example, while banana itself is not a complex product (everyone knows what banana tastes like), banana + almond smoothie is a complex product since it no longer tastes entirely like bananas, and even if you and I like bananas, you might like the banana + almond smoothie while I don’t. The banana flavor (taste, smell, texture) is lost in the complexity of blending and flavor of the other ingredients that make up the product. Clothes, shoes, fertilizers, food, movies and books are all examples of complex products.
Many a recommender system uses implicit feedback data from rather fleeting interactions (e.g. clicks, views, scrolls, search strings), but detailed and explicit ratings and feedback, and customer preferences are far richer, oftentimes more consistent and predictive.
Selection bias happens when data is missing not at random (MNAR). In a star rating scale of 1 through 5, we are more likely to see ratings in the extreme 1s and 5s because users tend to select and rate the items they like, and they are more likely to rate particularly bad or good items. The observed ratings are not a representative sample of all ratings.
“The most important quality of an evangelist is that the person loves the product and has an infectious enthusiasm for it.“ (source)
Netflix says, ”75% of what people watch is from some sort of recommendation.” (source) But I’m a bit more radical when I say solely responsible: can we sell 100% of products through recommendations, not by any other means?
From a data science perspective, when I say extremely relevant, your recommendation models should optimize for precision over recall. Show only a handful of products at a time that have an extremely high likelihood of purchase, for instance p > 0.95, because without a fallback mechanism (e.g. search, browsing filters), the cost of failure (e.g. fuming customers, cost of refund and shipping) is too big! This is related to truncating and hiding.
Intuitively, recall matters more than precision when users are doing an exhaustive research and want to look through as many relevant items as possible (e.g. if you want to learn about a new species of bird, you’d find and read as much information on it as you can).
As you may have noticed, I use the terms items and products interchangeably. I also say users to mean customers, and vice versa. Does it matter?
Additional resources:
Truncating, chunking and hiding all contribute to exposure bias and position bias in implicit feedback data. Exposure bias happens as users are only exposed to a part of specific items so that unobserved interactions do not always represent negative preference. In fact, if a user did not rate an item, it could mean two things: 1) the item does not match the user interest; or 2) the user is unaware of the item. It’s often difficult to distinguish real negative interactions from potentially positive ones.
Similarly, users are more likely to see popular items. Popularity bias is a form of exposure bias where recommender systems tend to suggest popular items more frequently than their popularity would warrant. This creates “the rich gets richer and the poor get poorer” phenomenon.
Position bias happens as users tend to interact with items in higher position of the recommendation list (left to right, top to bottom) regardless of the items’ actual relevance so that the interacted items might not be highly relevant.
Contextual bandits (explore vs exploit tradeoff) mitigate these biases to some degree.
My experience has been that the growth in the entire surface (search + browsing) is primarily driven by better-optimizing the content in the browsing and navigation to promote items that customers may not search.
Statistically speaking, one way to do this is have your ML model optimize a loss function that subtracts “the number of orders where an item was purchased from the browsing experience and where there was at least one search in the search experience,” from “the number of orders where an item was purchased from browsing but there was no interaction with search.”
If we know that a first-time customer (cold-start user) is vegan and we don’t currently offer a lot of vegan options, for example, then for the time being, their (predicted) LTV would be pretty small. Knowing this upfront helps us understand how valuable each customer is and how long it will take for us to break even on our CAC (customer acquisition cost).
As you’ll read in the next section, the secondary feedback questions can often inform the preference questions we ask in the customer profile.
Examples include StitchFix’s style shuffle and Daily Harvest’s test kitchens and habit and impact tracker.
Thanks for publishing this, excellent read. I might use this as a reference for my class project.
A very interesting article... I haven't thought about search that way. Please keep it up!